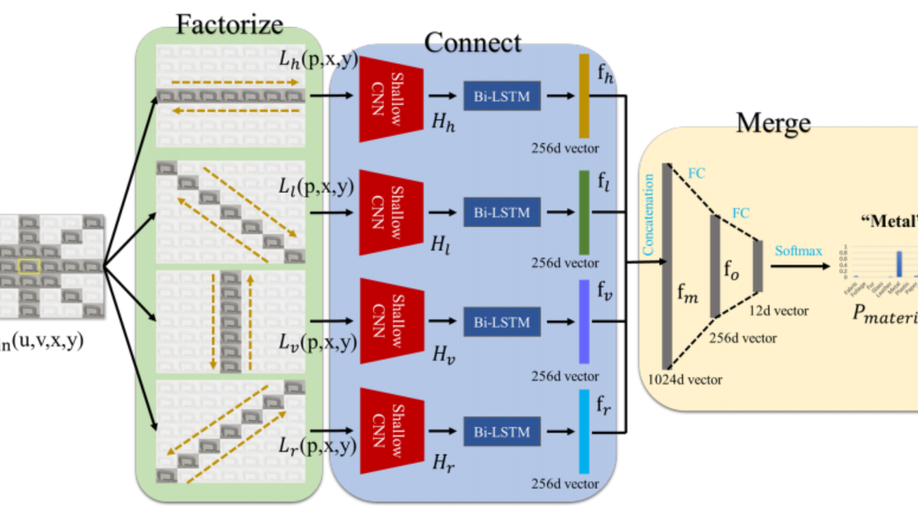
A Novel Deep-learning Pipeline for Light Field Image Based Material Recognition
The primitive basis of image based material recognition builds upon the fact that discrepancies in the reflectances of distinct materials lead to imaging differences under multiple viewpoints. LF cameras possess coherent abilities to capture multiple sub-aperture views (SAIs) within one exposure, which can provide appropriate multi-view sources for material recognition. In this paper, a unified Factorize-Connect-Merge (FCM) deep-learning pipeline is proposed to solve problems of light field image based material recognition. 4D light-field data as input is initially decomposed into consecutive 3D light-field slices. Shallow CNN is leveraged to extract low-level visual features of each view inside these slices. As to establish correspondences between these SAIs, Bidirectional Long-Short Term Memory (Bi-LSTM) network is built upon these low-level features to model the imaging differences. After feature selection including concatenation and dimension reduction, effective and robust feature representations for material recognition can be extracted from 4D light-field data. Experimental results indicate that the proposed pipeline can obtain remarkable performances on both tasks of single-pixel material classification and whole-image material segmentation. In addition, the proposed pipeline can potentially benefit and inspire other researchers who may also take LF images as input and need to extract 4D light-field representations for computer vision tasks such as object classification, semantic segmentation and edge detection.

High-fidelity View Synthesis for Light Field Imaging with Extended Pseudo 4DCNN
Multi-view properties of light field (LF) imaging enable exciting applications such as auto-refocusing, depth estimation and 3D reconstruction. However, limited angular resolution has become the main bottleneck of microlens-based plenoptic cameras towards more practical vision applications. Existing view synthesis methods mainly break the task into two steps, i.e. depth estimating and view warping, which are usually inefficient and produce artifacts over depth ambiguities. We have proposed an end-to-end deep learning framework named Pseudo 4DCNN to solve these problems in a conference paper. Rethinking on the overall paradigm, we further extend pseudo 4DCNN and propose a novel loss function which is applicable for all tasks of light field reconstruction i.e. EPI Structure Preserving (ESP) loss function. This loss function is proposed to attenuate the blurry edges and artifacts caused by averaging effect of L2 norm based loss function. Furthermore, the extended Pseudo 4DCNN is compared with recent state-of-the-art (SOTA) approaches on more publicly available light field databases, as well as self-captured light field biometrics and microscopy datasets. Experimental results demonstrate that the proposed framework can achieve better performances than vanilla Pseudo 4DCNN and other SOTA methods, especially in the terms of visual quality under occlusions. The source codes and self-collected datasets for reproducibility are available online.
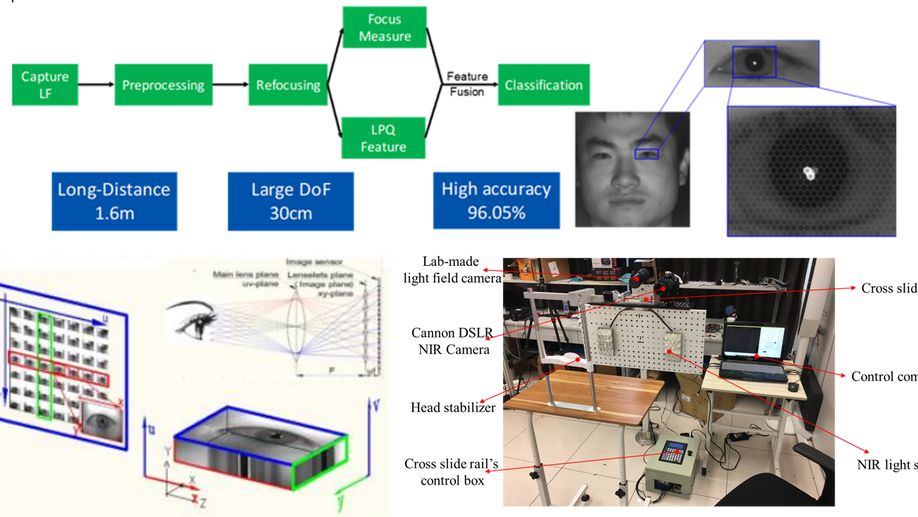
Iris Liveness Detection Based on Light Field Imaging
Light-field (LF) imaging is a new method to capture both intensity and direction information of visual objects, providing promising solutions to biometrics. Iris recognition is a reliable personal identification method, however it is also vulnerable to spoofing attacks, such as iris patterns printed on contact lens or paper. Therefore iris liveness detection is an important module in iris recognition systems. In this paper, an iris liveness detection approach is proposed to take full advantages of intrinsic characteristics in light-field iris imaging. LF iris images are captured by using lab-made LF cameras, based on which the geometric features as well as the texture features are extracted using the LF digital refocusing technology. These features are combined for genuine and fake iris image classification. Experiments were carried out based on the self-collected near-infrared LF iris database, and the average classification error rate (ACER) of the proposed method is 3.69%, which is 5.94% lower than the best state-of-the-art method. Experimental results indicate the proposed method is able to work effectively and accurately to prevent spoofing attacks such as printed and screen-displayed iris input attacks.
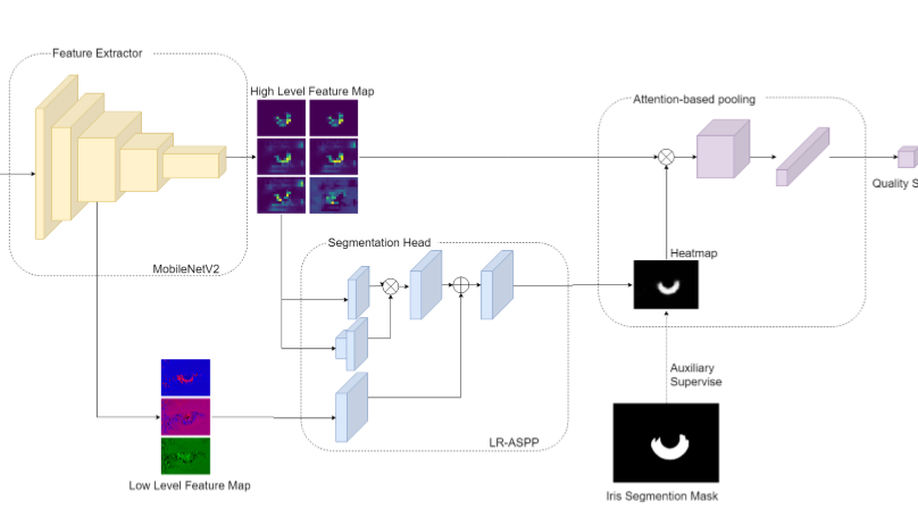
Recognition Oriented Iris Image Quality Assessment in the Feature Space
A large portion of iris images captured in real world scenarios are poor quality due to the uncontrolled environment and the non-cooperative subject. To ensure that the recognition algorithm is not affected by low-quality images, traditional hand-crafted factors based methods discard most images, which will cause system timeout and disrupt user experience. In this paper, we propose a recognition-oriented quality metric and assessment method for iris image to deal with the problem. The method regards the iris image embeddings Distance in Feature Space (DFS) as the quality metric and the prediction is based on deep neural networks with the attention mechanism. The quality metric proposed in this paper can significantly improve the performance of the recognition algorithm while reducing the number of images discarded for recognition, which is advantageous over hand-crafted factors based iris quality assessment methods. The relationship between Image Rejection Rate (IRR) and Equal Error Rate (EER) is proposed to evaluate the performance of the quality assessment algorithm under the same image quality distribution and the same recognition algorithm. Compared with hand-crafted factors based methods, the proposed method is a trial to bridge the gap between the image quality assessment and biometric recognition.
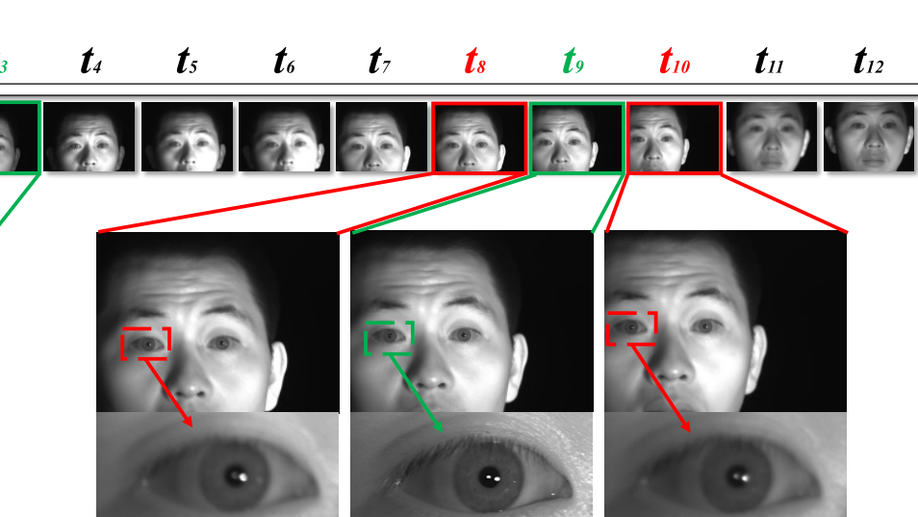
All-in-Focus Iris Camera With a Great Capture Volume
Imaging volume of an iris recognition system has been restricting the throughput and cooperation convenience in biometric applications. Numerous improvement trials are still impractical to supersede the dominant fixed-focus lens in stand-off iris recognition due to incremental performance increase and complicated optical design. In this study, we develop a novel all-in-focus iris imaging system using a focus-tunable lens and a 2D steering mirror to greatly extend capture volume by spatiotemporal multiplexing method. Our iris imaging depth of field extension system requires no mechanical motion and is capable to adjust the focal plane at extremely high speed. In addition, the motorized reflection mirror adaptively steers the light beam to extend the horizontal and vertical field of views in an active manner. The proposed all-in-focus iris camera increases the depth of field up to 3.9 m which is a factor of37.5 compared with conventional long focal lens. We also experimentally demonstrate the capability of this 3D light beam steering imaging system in real-time multi-person iris refocusing using dynamic focal stacks and the potential of continuous iris recognition for moving participants.

ScleraSegNet: An Attention Assisted U-Net Model for Accurate Sclera Segmentation
Accurate sclera segmentation is critical for successful sclera recognition. However, studies on sclera segmentation algorithms are still limited in the literature. In this paper, we propose a novel sclera segmentation method based on the improved U-Net model, named as ScleraSegNet. We perform in-depth analysis regarding the structure of U-Net model, and propose to embed an attention module into the central bottleneck part between the contracting path and the expansive path of U-Net to strengthen the ability of learning discriminative representations. We compare different attention modules and find that channel-wise attention is the most effective in improving the performance of the segmentation network. Besides, we evaluate the effectiveness of data augmentation process in improving the generalization ability of the segmentation network. Experiment results show that the best performing configuration of the proposed method achieves state-of-the-art performance with F-measure values of 91.43%, 89.54% on UBIRIS.v2 and MICHE, respectively.
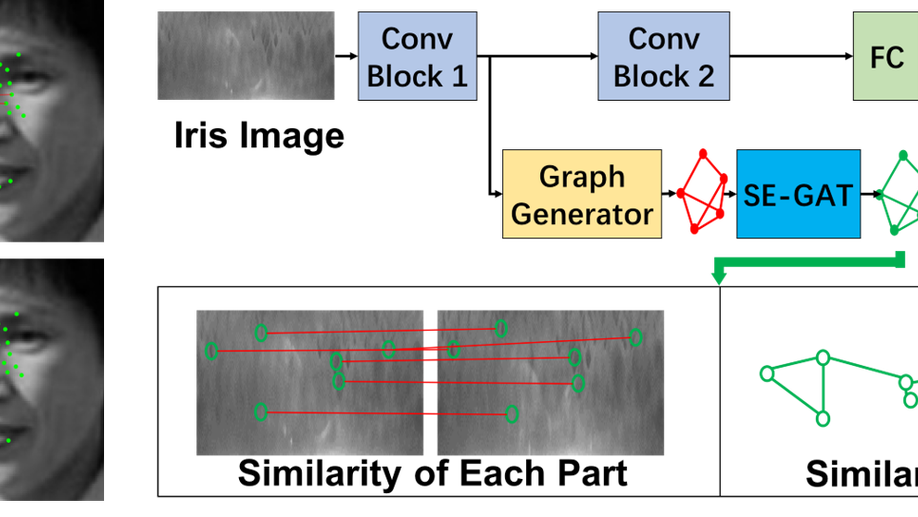
Dynamic Graph Representation for Occlusion Handling in Biometrics
The generalization ability of Convolutional neural networks (CNNs) for biometrics drops greatly due to the adverse effects of various occlusions. To this end, we propose a novel unified framework integrated the merits of both CNNs and graphical models to learn dynamic graph representations for occlusion problems in biometrics, called Dynamic Graph Representation (DGR). Convolutional features onto certain regions are re-crafted by a graph generator to establish the connections among the spatial parts of biometrics and build Feature Graphs based on these node representations. Each node of Feature Graphs corresponds to a specific part of the input image and the edges express the spatial relationships between parts. By analyzing the similarities between the nodes, the framework is able to adaptively remove the nodes representing the occluded parts. During dynamic graph matching, we propose a novel strategy to measure the distances of both nodes and adjacent matrixes. In this way, the proposed method is more convincing than CNNs-based methods because the dynamic graph method implies a more illustrative and reasonable inference of the biometrics decision. Experiments conducted on iris and face demonstrate the superiority of the proposed framework, which boosts the accuracy of occluded biometrics recognition by a large margin comparing with baseline methods.
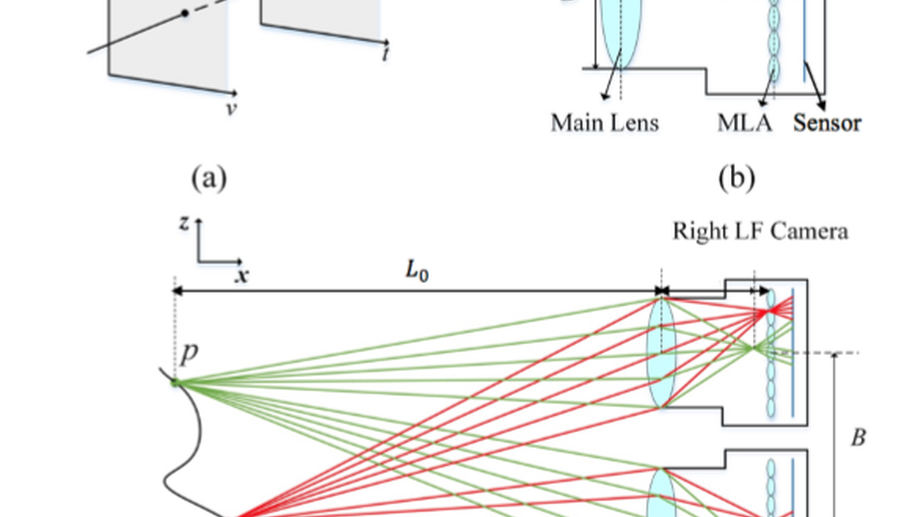
Binocular Light-Field: Imaging Theory and Occlusion-Robust Depth Perception Application
Binocular stereo vision (SV) has been widely used to reconstruct the depth information, but it is quite vulnerable to scenes with strong occlusions. As an emerging computational photography technology, light-field (LF) imaging brings about a novel solution to passive depth perception by recording multiple angular views in a single exposure. In this paper, we explore binocular SV and LF imaging to form the binocular-LF imaging system. An imaging theory is derived by modeling the imaging process and analyzing disparity properties based on the geometrical optics theory. Then an accurate occlusion-robust depth estimation algorithm is proposed by exploiting multibaseline stereo matching cues and defocus cues. The occlusions caused by binocular SV and LF imaging are detected and handled to eliminate the matching ambiguities and outliers. Finally, we develop a binocular-LF database and capture realworld scenes by our binocular-LF system to test the accuracy and robustness. The experimental results demonstrate that the proposed algorithm definitely recovers high quality depth maps with smooth surfaces and precise geometric shapes, which tackles the drawbacks of binocular SV and LF imaging simultaneously.
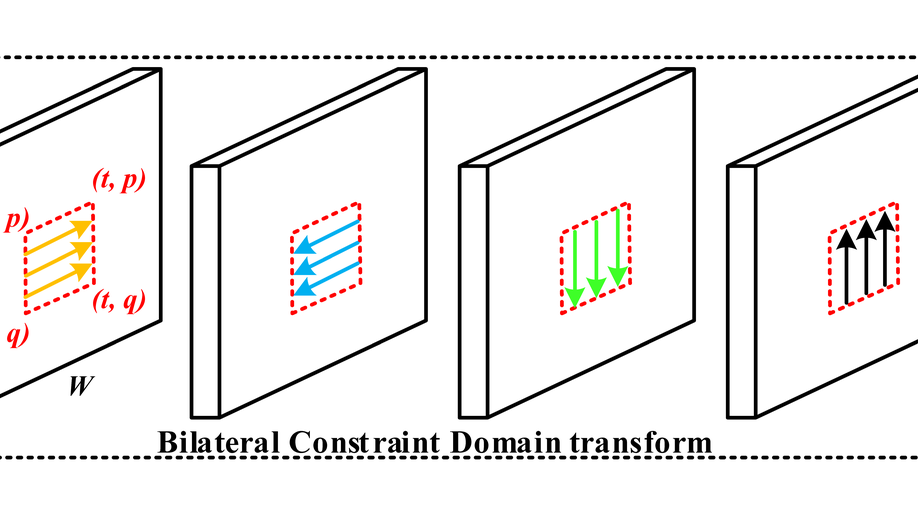
Seg-Edge Bilateral Constraint Network for Iris Segmentation
In this paper, we present an end-to-end model, namely Seg-Edge bilateral constraint network. The iris edge map generated from rich convolutional layers optimize the iris segmentation by aligning it with the iris boundary. The iris region produced by the coarse segmentation limits the scope. It makes the edge filtering pay more attention to the interesting target. We compress the model while keeping the performance levels almost intact and even better by using l1-norm. The proposed model advances the state-of-the-art iris segmentation accuracies.
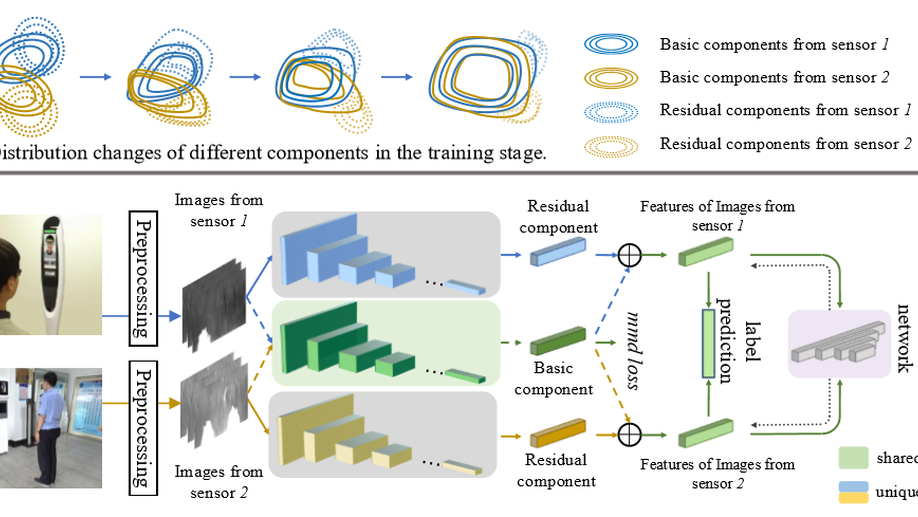
Cross-sensor iris recognition using adversarial strategy and sensor-specific information
Due to the growing demand of iris biometrics, lots of new sensors are being developed for high-quality image acquisition. However, upgrading the sensor and re-enrolling for users is expensive and time-consuming. This leads to a dilemma where enrolling on one type of sensor but recognizing on the others. For this cross-sensor matching, the large gap between distributions of enrolling and recognizing images usually results in degradation in recognition performance. To alleviate this degradation, we propose Cross-sensor iris network (CSIN) by applying the adversarial strategy and weakening interference of sensor-specific information. Specifically, there are three valuable efforts towards learning discriminative iris features. Firstly, the proposed CSIN adds extra feature extractors to generate residual components containing sensor-specific information and then utilizes these components to narrow the distribution gap. Secondly, an adversarial strategy is borrowed from Generative Adversarial Networks to align feature distributions and further reduce the discrepancy of images caused by sensors. Finally, we extend triplet loss and propose instance-anchor loss to pull the instances of the same class together and push away from others. It is worth mentioning that the proposed method doesn’t need pair-same data or triplet, which reduced the cost of data preparation. Experiments on two real-world datasets validate the effectiveness of the proposed method in cross-sensor iris recognition.
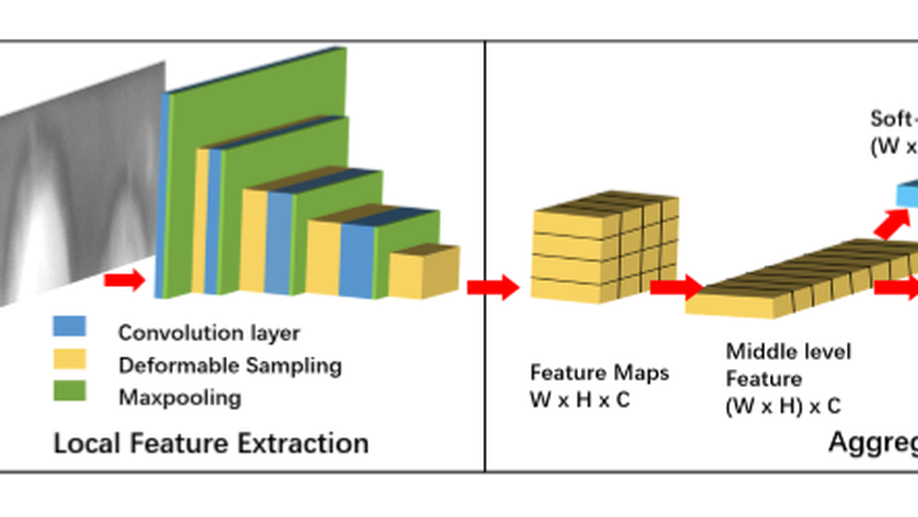
Alignment Free and Distortion Robust Iris Recognition
Iris recognition is a reliable personal identification method but there is still much room to improve its accuracy especially in less-constrained situations. For example, free movement of head pose may cause large rotation difference between iris images. And illumination variations may cause irregular distortion of iris texture. To match intra-class iris images with head rotation robustly, the existing soadminlutions usually need a precise alignment operation by exhaustive search within a determined range in iris image preprosessing or brute-force searching the minimum Hamming distance in iris feature matching. In the wild enviroments, iris rotation is of much greater uncertainty than that in constrained situations and exhaustive search within a determined range is impracticable. This paper presents a unified feature-level solution to both alignment free and distortion robust iris recognition in the wild. A new deep learning based method named Alignment Free Iris Network (AFINet) is proposed, which utilizes a trainable VLAD (Vector of Locally Aggregated Descriptors) encoder called NetVLAD [18] to decouple the correlations between local representations and their spatial positions. And deformable convolution [5] is leveraged to overcome iris texture distortion by dense adaptive sampling. The results of extensive experiments on three public iris image databases and the simulated degradation databases show that AFINet significantly outperforms state-of-art iris recognition methods.
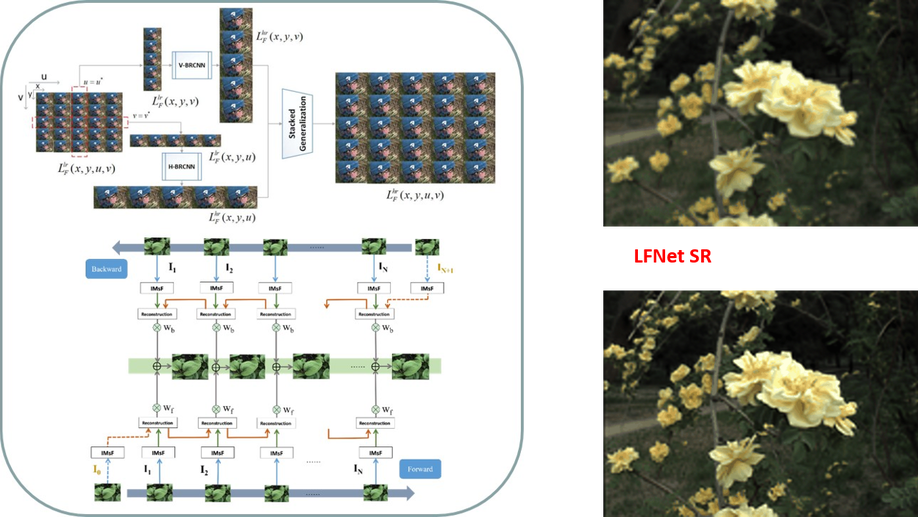
LFNet: A Novel Bidirectional Recurrent Convolutional Neural Network for Light-Field Image Super-Resolution
The low spatial resolution of light-field image poses significant difficulties in exploiting its advantage. To mitigate the dependency of accurate depth or disparity information as priors for light-field image super-resolution, we propose an implicitly multi-scale fusion scheme to accumulate contextual information from multiple scales for super-resolution reconstruction. The implicitly multi-scale fusion scheme is then incorporated into bidirectional recurrent convolutional neural network, which aims to iteratively model spatial relations between horizontally or vertically adjacent sub-aperture images of light-field data. Within the network, the recurrent convolutions are modified to be more effective and flexible in modeling the spatial correlations between neighboring views. A horizontal sub-network and a vertical sub-network of the same network structure are ensembled for final outputs via stacked generalization. Experimental results on synthetic and real-world data sets demonstrate that the proposed method outperforms other state-of-the-art methods by a large margin in peak signal-to-noise ratio and gray-scale structural similarity indexes, which also achieves superior quality for human visual systems. Furthermore, the proposed method can enhance the performance of light field applications such as depth estimation.
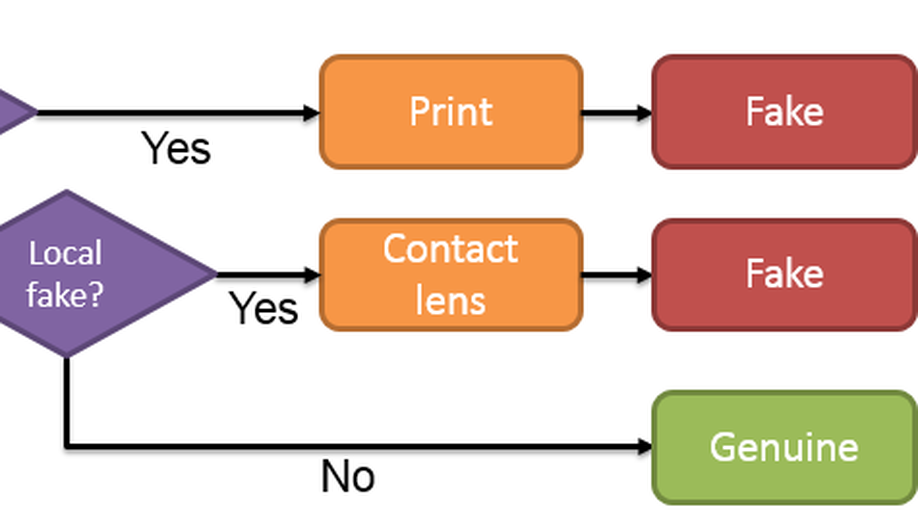
Hierarchical Multi-class Iris Classification for Liveness Detection
In modern society, iris recognition has become increasingly popular. The security risk of iris recognition is increasing rapidly because of the attack by various patterns of fake iris. A German hacker organization called Chaos Computer Club cracked the iris recognition system of Samsung Galaxy S8 recently. In view of these risks, iris liveness detection has shown its significant importance to iris recognition systems. The state-of-the-art algorithms mainly rely on hand-crafted texture features which can only identify fake iris images with single pattern. In this paper, we proposed a Hierarchical Multiclass Iris Classification (HMC) for liveness detection based on CNN. HMC mainly focuses on iris liveness detection of multipattern fake iris. The proposed method learns the features of different fake iris patterns by CNN and classifies the genuine or fake iris images by hierarchical multi-class classification. This classification takes various characteristics of different fake iris patterns into account. All kinds of fake iris patterns are divided into two categories by their fake areas. The process is designed as two steps to identify two categories of fake iris images respectively. Experimental results demonstrate an extremely higher accuracy of iris liveness detection than other state-of-the-art algorithms. The proposed HMC remarkably achieves the best results with nearly 100% accuracy on NDContact, CASIA-Iris-Interval, CASIA-Iris-Syn and LivDetIris-2017-Warsaw datasets. The method also achieves the best results with 100% accuracy on a hybrid dataset which consists of ND-Contact and LivDet-Iris-2017-Warsaw dataset
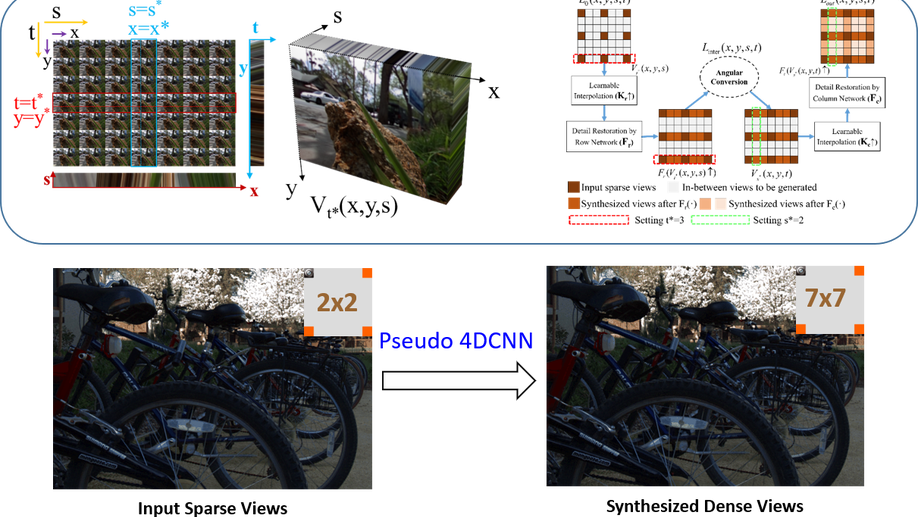
End-to-End View Synthesis for Light Field Imaging with Pseudo 4DCNN
Limited angular resolution has become the main bottleneck of microlens-based plenoptic cameras towards practical vision applications. Existing view synthesis methods mainly break the task into two steps, i.e. depth estimating and view warping, which are usually inefficient and produce artifacts over depth ambiguities. In this paper, an end-to-end deep learning framework is proposed to solve these problems by exploring Pseudo 4DCNN. Specifically, 2D strided convolutions operated on stacked EPIs and detail-restoration 3D CNNs connected with angular conversion are assembled to build the Pseudo 4DCNN. The key advantage is to efficiently synthesize dense 4D light fields from a sparse set of input views. The learning framework is well formulated as an entirely trainable problem, and all the weights can be recursively updated with standard backpropagation. The proposed framework is compared with state-of-the-art approaches on both genuine and synthetic light field databases, which achieves significant improvements of both image quality (+2 dB higher) and computational efficiency (over 10X faster). Furthermore, the proposed framework shows good performances in real-world applications such as biometrics and depth estimation.
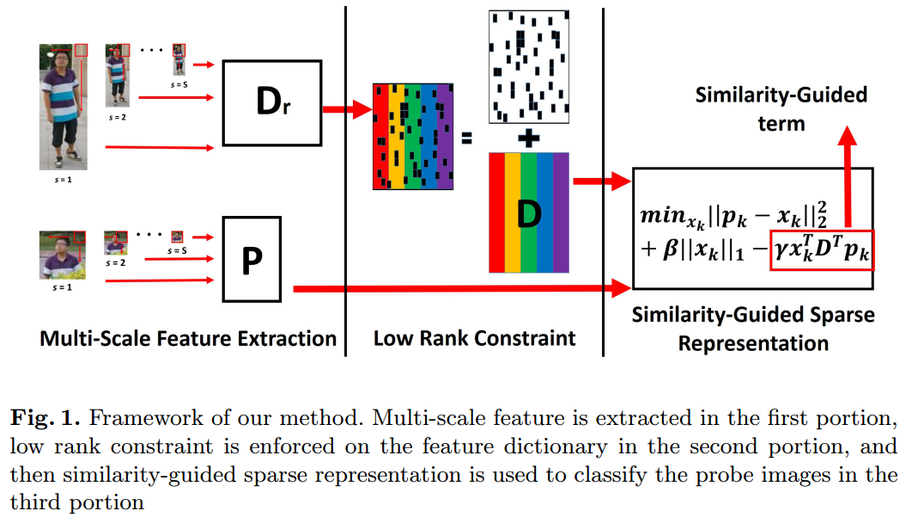
Robust Partial Person Re-Identification Based on Similarity-Guided Sparse Representation
In this paper, we study the problem of partial person reidentification (re-id). This problem is more difficult than general person re-identification because the body in probe image is not full. We propose a novel method, similarity-guided sparse representation (SG-SR), as a robust solution to improve the discrimination of the sparse coding. There are three main components in our method. In order to include multi-scale information, a dictionary consisting of features extracted from multiscale patches is established in the first stage. A low rank constraint is then enforced on the dictionary based on the observation that its subspaces of each class should have low dimensions. After that, a classification model is built based on a novel similarity-guided sparse representation which can choose vectors that are more similar to the probe feature vector. The results show that our method outperforms existing partial person re-identification methods significantly and achieves state-of-theart accuracy.

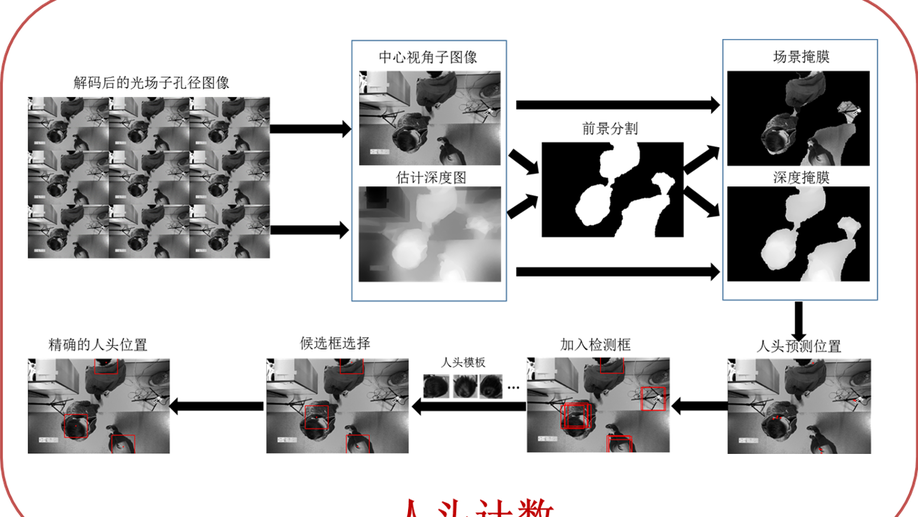
4D light-field sensing system for people counting
Counting the number of people is still an important task in social security applications, and a few methods based on video surveillance have been proposed in recent years. In this paper, we design a novel optical sensing system to directly acquire the depth map of the scene from one light-field camera. The light-field sensing system can count the number of people crossing the passageway, and record the direction and intensity of rays at a snapshot without any assistant light devices. Depth maps are extracted from the raw light-ray sensing data. Our smart sensing system is equipped with a passive imaging sensor, which is able to naturally discern the depth difference between the head and shoulders for each person. Then a human model is built. Through detecting the human model from light-field images, the number of people passing the scene can be counted rapidly. We verify the feasibility of the sensing system as well as the accuracy by capturing real-world scenes passing single and multiple people under natural illumination.